
Pandasの配列には1次配列をシリーズ、2次配列をデータフレームと言いデータを扱う上で基礎となるものです.本稿ではシリーズおよびデータフレームの作成方法とデータ内の要素値を取得する方法について詳しく解説しております.
スポンサーリンク
シリーズ概要
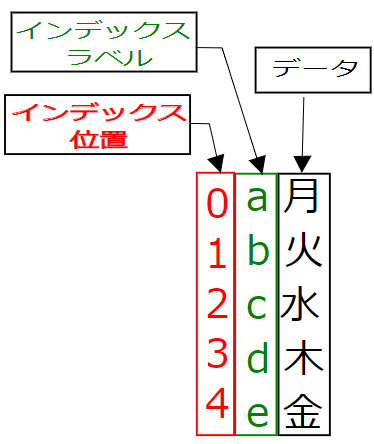
シリーズとはPandasのデータ構成の最も基本的なものです.シリーズは一次配列のデータ()と,インデックから構成されており,インデックを使ってデータの各要素値を参照したり処理をすることができます.インデックスはデータに与えられたラベルであり,文字や数値を使う事ができます.シリーズは下図のような構成になっています.シリーズデータ作成時にインデクス位置番号が0番から順に付加されます.
・シリーズを作成する
pandas.Serise()関数にリストやNumpy配列を渡すことでシリーズを作成することができます.
pandas.Serise(data=None, index=None, dtype=None, name=None, copy=False)
| 引数 | 概要 |
| data | 配列,配列に準じるもの、スカラー値 |
| index | インデクスラベルの値, 1次元配列 データと同じ数である必要があります. |
| dtype | str,numpy.dtype,またはExtensionDtype、オプション 出力シリーズのデータ型、指定しない場合これらのデータは推定されます. |
| name | シリーズに付ける名前 |
| copy | bool,(デフォルトFalse) 入力データをコピーします. |
・シリーズをリストとnumpy配列から作成します.
リストには惑星の名前とNumpy配列には地球からの距離(光分)のデータを作成したものをシリーズにします.
[IN]
import numpy as np
import pandas as pd
# リストデータからシリーズ作成
lis_planet=["水星","金星","地星","火星","木星"]
ser_plane=pd.Series(lis_planet)
#numpy配列からシリーズ作成
arr_dis=np.array([4879,12104,1256,6792,142984])
ser_dis=pd.Series(arr_dis)
print("リストから作成 \n", ser_plane)
print("\nNumpy配列から作成 \n", ser_dis)[OUT]
リストから作成
0 水星
1 金星
2 地星
3 火星
4 木星
dtype: object
Numpy配列から作成
0 4879
1 12104
2 1256
3 6792
4 142984
dtype: int32 プリント表示するとインデックス番号と配列の型式(dtype)が表示されました.インデックス番号は0番から始まっている事が確認できます.
シリーズ名とインデックスラベルを付ける
シリーズ名をSeriseオプションのnameより付けることができます.nameを使ってシリーズをデータフレームに結合したりします.シリーズにインデックスラベル付けることで対応したデータ値を参照できます.
・シリーズにnameとインデックスを与えていきます.
先程の例で地球から惑星名の距離(光分)をシリーズデータとして,名前を”planet”とし、インデクスには惑星の名前をリストで渡します.
[IN]
mport numpy as np
import pandas as pd
lis_planet=["水星","金星","地星","火星","木星"]
arr_dis=np.array([4879,12104,1256,6792,142984])
ser_dis=pd.Series(arr_dis,name="planet",index=lis_planet)
print("シリーズ \n",ser_dis)[OUT]
シリーズ
水星 4879
金星 12104
地球 1256
火星 6792
木星 142984
Name: planet, dtype: int32
名前がplanetでインデックスが惑星名のシリーズが作成できました.
シリーズからデータ値を取得する方法
・インデック名からシリーズのデータ値を取得します.
値を取得したいインデックスを角括弧で囲もシリーズよりデータ値を取得します.
シリーズ名[インデックス]
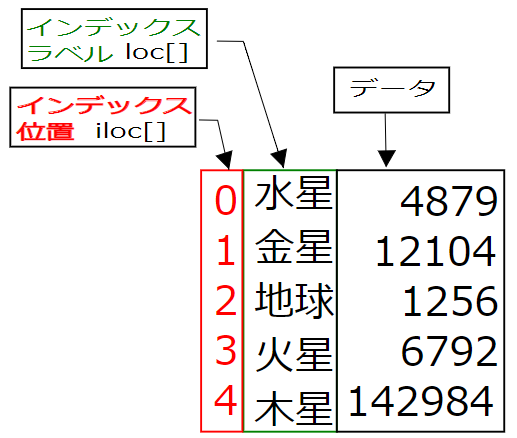
・位置インデックスloc[]とiloc[]を使ってデータの値を取得する.
loc[]はインデックの値によってシリーズの値を取得します.
iloc[]は、シリーズデータを0から整数を割り振った位置を指示し、値を取得します.
・シリーズからデータ値を取得するプログラムを作成します.
[IN]
import numpy as np
import pandas as pd
lis_planet=["水星","金星","地球","火星","木星"]
arr_dis=np.array([4879,12104,1256,6792,142984])
ser_dis=pd.Series(arr_dis,name="planet",index=lis_planet)
print("水星 \n" ,ser_dis[ "水星" ] )
print("\n 金星から火星 \n" ,ser_dis[ "金星" : "火星" ])
print('\n loc["地球"] \n' ,ser_dis.loc["地球"] )
print("\n iloc[2] \n" ,ser_dis.iloc[2] )[OUT]
水星
4879
金星から火星
金星 12104
地球 1256
火星 6792
Name: planet, dtype: int32
loc["地球"]
1256
iloc[2]
1256サンプルプログラムのデータフレームとインデックスラベルとインデックス位置の関係を下図に記載します.
データーフレームの概要
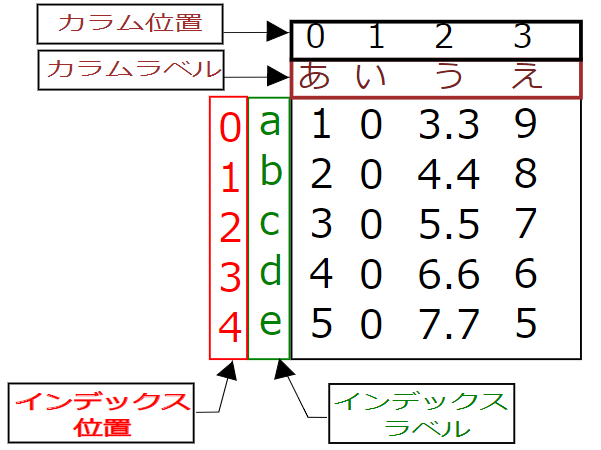
データフレームは2次元配列で構成されており,縦にインデクスラベル,横にカラムラベルが与えられています.データフレーム生成時に縦にインデックス位置番号、横にカラム位置番号が0から順に付加されます.これは内部的の持っているものでプリントしても表示されません.
データフレームを作成する
pandas.DataFrame()関数に2次元配列のリストやNumpy配列を渡すことでデータフレームを作成することができます.
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
| 引数 | 概要 |
| data | 配列,配列に準じるもの、スカラー値 |
| index | インデクスラベルの値, 1次元配列 データと同じ数である必要があります. |
| dtype | str,numpy.dtype,またはExtensionDtype、オプション 出力シリーズのデータ型、指定しない場合これらのデータは推定されます. |
| name | シリーズに付ける名前 |
| copy | bool,(デフォルトFalse) 入力データをコピーします. |
・データフレームをリストとNump配列から作成します.
[IN]
import numpy as np
import pandas as pd
#リストからデータフレーム作成
a_list=[[1,2],
[3,4]]
df_a = pd.DataFrame(a_list)
#numoy配列からデータフレーム作成
b_arr=np.array([[11,12,13],
[21,22,23]])
df_b = pd.DataFrame(b_arr)
print("リストから作成 \n", df_a)
print("\nNumpy配列から作成 \n",df_b)[OUT]
リストから作成
0 1
0 1 2
1 3 4
Numpy配列から作成
0 1 2
0 11 12 13
1 21 22 23インデックスラベルとカラムラベルは特に指定がないと0番から順に作成されます.
・データフレームにインデックスラベルとカラムラベルを付加して作成
DataFrameの引数としてindexからインデックスラベル,columnsからカラムラベルを設定することができます.
[IN]
import numpy as np
import pandas as pd
#yoko = ["city ","population","Area[km^2]"]
yoko = ["city ","population","Area[km^2]"]
tate = ["No1","No2","No3"]
a_list=np.array([["Saga ", 232359 , 432 ],
["Izumo ", 171995 , 624 ],
["Kagawa ", 949357 ,1877 ]])
df_b = pd.DataFrame(a_list,index=tate, columns=yoko )
print(df_b)[OUT]
city population Area[km^2]
No1 Saga 232359 432
No2 Izumo 171995 624
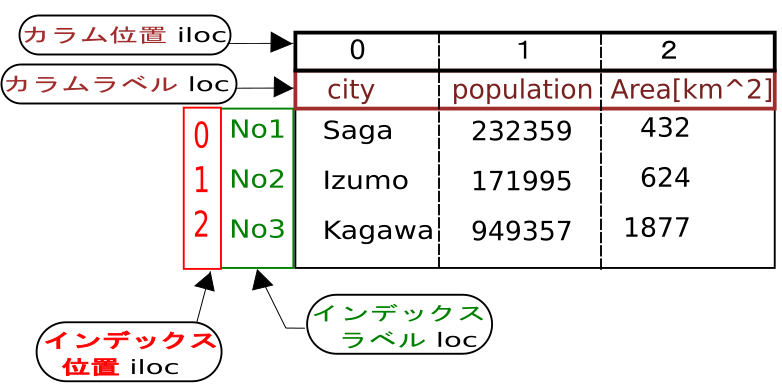
No3 Kagawa 949357 1877データフレームの要素値を取得する.
データフレーム内の要素値を取得するには,loc[]かiloc[]を使います.
df.loc[“インデックスラベル”,”カラムラベル”]
df.iloc[位置インデックス,位置カラム ]
注) dfは操作したいデータフレーム名
・データフレーム内の要素値をloc[]とiloc[]使って取得します.
[IN]
import numpy as np
import pandas as pd
#yoko = ["city ","population","Area[km^2]"]
yoko = ["city ","population","Area[km^2]"]
tate = ["No1","No2","No3"]
a_list=np.array([["Saga ", 232359 , 432 ],
["Izumo ", 171995 , 624 ],
["Kagawa ", 949357 ,1877 ]])
df_b = pd.DataFrame(a_list,index=tate, columns=yoko )
print("元のデータフレーム\n",df_b)
print("\n locで取得 \n", df_b.loc["No2" ,"population" ] )
print("\n ilocで取得 \n", df_b.iloc[0:2, 1:3 ] )[OUT]
元のデータフレーム
city population Area[km^2]
No1 Saga 232359 432
No2 Izumo 171995 624
No3 Kagawa 949357 1877
locで取得
171995
ilocで取得
population Area[km^2]
No1 232359 432
No2 171995 624下図にサンプルでのデータフレームのiloc.locの関係を示した図を記載します.
まとめ
以上でpanndasのシリーズ及びデータフレームを作成して,配列内の要素値を参照することができるようになったと思います.
スポンサーリンク

コメント